
Small. Fast. Reliable.
Choose any three.
Choose any three.
SQLite reads and writes small blobs (for example, thumbnail images) 35% faster¹ than the same blobs can be read from or written to individual files on disk using fread() or fwrite().
Furthermore, a single SQLite database holding 10-kilobyte blobs uses about 20% less disk space than storing the blobs in individual files.
The performance difference arises (we believe) because when working from an SQLite database, the open() and close() system calls are invoked only once, whereas open() and close() are invoked once for each blob when using blobs stored in individual files. It appears that the overhead of calling open() and close() is greater than the overhead of using the database. The size reduction arises from the fact that individual files are padded out to the next multiple of the filesystem block size, whereas the blobs are packed more tightly into an SQLite database.
The measurements in this article were made during the week of 2017-06-05 using a version of SQLite in between 3.19.2 and 3.20.0. You may expect future versions of SQLite to perform even better.
¹The 35% figure above is approximate. Actual timings vary depending on hardware, operating system, and the details of the experiment, and due to random performance fluctuations on real-world hardware. See the text below for more detail. Try the experiments yourself. Report significant deviations on the SQLite forum.
The 35% figure is based on running tests on every machine that the author has easily at hand. Some reviewers of this article report that SQLite has higher latency than direct I/O on their systems. We do not yet understand the difference. We also see indications that SQLite does not perform as well as direct I/O when experiments are run using a cold filesystem cache.
So let your take-away be this: read/write latency for SQLite is competitive with read/write latency of individual files on disk. Often SQLite is faster. Sometimes SQLite is almost as fast. Either way, this article disproves the common assumption that a relational database must be slower than direct filesystem I/O.
A 2022 study (alternative link on GitHub) found that SQLite is roughly twice as fast at real-world workloads compared to Btrfs and Ext4 on Linux.
Jim Gray and others studied the read performance of BLOBs versus file I/O for Microsoft SQL Server and found that reading BLOBs out of the database was faster for BLOB sizes less than between 250KiB and 1MiB. (Paper). In that study, the database still stores the filename of the content even if the content is held in a separate file. So the database is consulted for every BLOB, even if it is only to extract the filename. In this article, the key for the BLOB is the filename, so no preliminary database access is required. Because the database is never used at all when reading content from individual files in this article, the threshold at which direct file I/O becomes faster is smaller than it is in Gray's paper.
The Internal Versus External BLOBs article on this website is an earlier investigation (circa 2011) that uses the same approach as the Jim Gray paper — storing the blob filenames as entries in the database — but for SQLite instead of SQL Server.
I/O performance is measured using the kvtest.c program from the SQLite source tree. To compile this test program, first gather the kvtest.c source file into a directory with the SQLite amalgamation source files "sqlite3.c" and "sqlite3.h". Then on unix, run a command like the following:
gcc -Os -I. -DSQLITE_DIRECT_OVERFLOW_READ \ kvtest.c sqlite3.c -o kvtest -ldl -lpthread
Or on Windows with MSVC:
cl -I. -DSQLITE_DIRECT_OVERFLOW_READ kvtest.c sqlite3.c
Instructions for compiling for Android are shown below.
Use the resulting "kvtest" program to generate a test database with 100,000 random uncompressible blobs, each with a random size between 8,000 and 12,000 bytes using a command like this:
./kvtest init test1.db --count 100k --size 10k --variance 2k
If desired, you can verify the new database by running this command:
./kvtest stat test1.db
Next, make copies of all the blobs into individual files in a directory using a command like this:
./kvtest export test1.db test1.dir
At this point, you can measure the amount of disk space used by the test1.db database and the space used by the test1.dir directory and all of its content. On a standard Ubuntu Linux desktop, the database file will be 1,024,512,000 bytes in size and the test1.dir directory will use 1,228,800,000 bytes of space (according to "du -k"), about 20% more than the database.
The "test1.dir" directory created above puts all the blobs into a single folder. It was conjectured that some operating systems would perform poorly when a single directory contains 100,000 objects. To test this, the kvtest program can also store the blobs in a hierarchy of folders with no more than 100 files and/or subdirectories per folder. The alternative on-disk representation of the blobs can be created using the --tree command-line option to the "export" command, like this:
./kvtest export test1.db test1.tree --tree
The test1.dir directory will contain 100,000 files with names like "000000", "000001", "000002" and so forth but the test1.tree directory will contain the same files in subdirectories like "00/00/00", "00/00/01", and so on. The test1.dir and test1.test directories take up approximately the same amount of space, though test1.test is very slightly larger due to the extra directory entries.
All of the experiments that follow operate the same with either "test1.dir" or "test1.tree". Very little performance difference is measured in either case, regardless of operating system.
Measure the performance for reading blobs from the database and from individual files using these commands:
./kvtest run test1.db --count 100k --blob-api ./kvtest run test1.dir --count 100k --blob-api ./kvtest run test1.tree --count 100k --blob-api
Depending on your hardware and operating system, you should see that reads from the test1.db database file are about 35% faster than reads from individual files in the test1.dir or test1.tree folders. Results can vary significantly from one run to the next due to caching, so it is advisable to run tests multiple times and take an average or a worst case or a best case, depending on your requirements.
The --blob-api option on the database read test causes kvtest to use the sqlite3_blob_read() feature of SQLite to load the content of the blobs, rather than running pure SQL statements. This helps SQLite to run a little faster on read tests. You can omit that option to compare the performance of SQLite running SQL statements. In that case, the SQLite still out-performs direct reads, though by not as much as when using sqlite3_blob_read(). The --blob-api option is ignored for tests that read from individual disk files.
Measure write performance by adding the --update option. This causes the blobs to be overwritten in place with another random blob of exactly the same size.
./kvtest run test1.db --count 100k --update ./kvtest run test1.dir --count 100k --update ./kvtest run test1.tree --count 100k --update
The writing test above is not completely fair, since SQLite is doing power-safe transactions whereas the direct-to-disk writing is not. To put the tests on a more equal footing, add either the --nosync option to the SQLite writes to disable calling fsync() or FlushFileBuffers() to force content to disk, or using the --fsync option for the direct-to-disk tests to force them to invoke fsync() or FlushFileBuffers() when updating disk files.
By default, kvtest runs the database I/O measurements all within a single transaction. Use the --multitrans option to run each blob read or write in a separate transaction. The --multitrans option makes SQLite much slower, and uncompetitive with direct disk I/O. This option proves, yet again, that to get the most performance out of SQLite, you should group as much database interaction as possible within a single transaction.
There are many other testing options, which can be seen by running the command:
./kvtest help
The chart below shows data collected using kvtest.c on five different systems:
All machines use SSD except Win7 which has a hard-drive. The test database is 100K blobs with sizes uniformly distributed between 8K and 12K, for a total of about 1 gigabyte of content. The database page size is 4KiB. The -DSQLITE_DIRECT_OVERFLOW_READ compile-time option was used for all of these tests. Tests were run multiple times. The first run was used to warm up the cache and its timings were discarded.
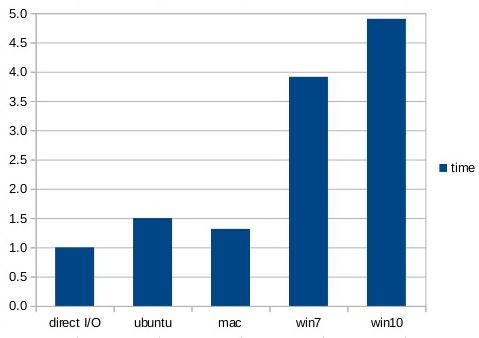
The chart below shows average time to read a blob directly from the filesystem versus the time needed to read the same blob from the SQLite database. The actual timings vary considerably from one system to another (the Ubuntu desktop is much faster than the Galaxy S3 phone, for example). This chart shows the ratio of the times needed to read blobs from a file divided by the time needed to read them from the database. The left-most column in the chart is the normalized time to read from the database, for reference.
In this chart, an SQL statement ("SELECT v FROM kv WHERE k=?1") is prepared once. Then for each blob, the blob key value is bound to the ?1 parameter and the statement is evaluated to extract the blob content.
The chart shows that on Windows10, content can be read from the SQLite database about 5 times faster than it can be read directly from disk. On Android, SQLite is only about 35% faster than reading from disk.
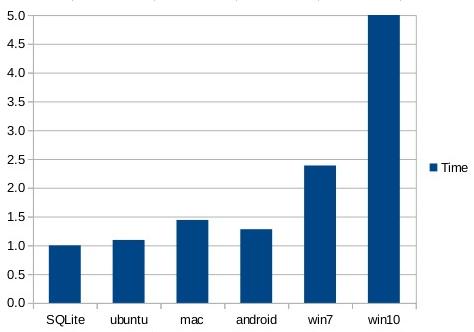
The performance can be improved slightly by bypassing the SQL layer and reading the blob content directly using the sqlite3_blob_read() interface, as shown in the next chart:
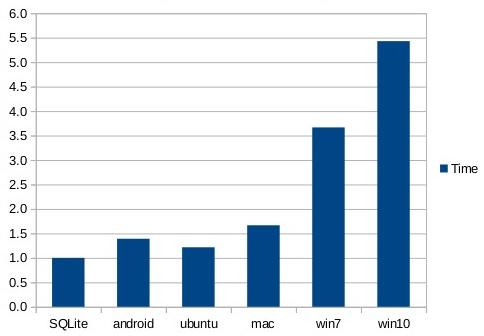
Further performance improvements can be made by using the memory-mapped I/O feature of SQLite. In the next chart, the entire 1GB database file is memory mapped and blobs are read (in random order) using the sqlite3_blob_read() interface. With these optimizations, SQLite is twice as fast as Android or MacOS-X and over 10 times faster than Windows.
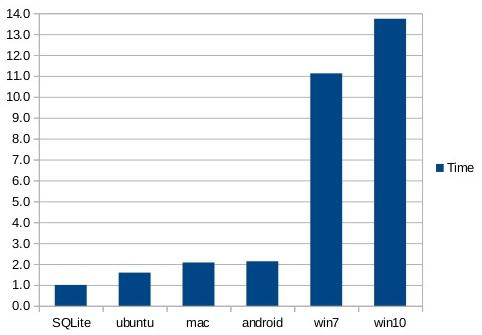
The third chart shows that reading blob content out of SQLite can be twice as fast as reading from individual files on disk for Mac and Android, and an amazing ten times faster for Windows.
Writes are slower. On all systems, using both direct I/O and SQLite, write performance is between 5 and 15 times slower than reads.
Write performance measurements were made by replacing (overwriting) an entire blob with a different blob. All of the blobs in these experiments are random and incompressible. Because writes are so much slower than reads, only 10,000 of the 100,000 blobs in the database are replaced. The blobs to be replaced are selected at random and are in no particular order.
The direct-to-disk writes are accomplished using fopen()/fwrite()/fclose(). By default, and in all the results shown below, the OS filesystem buffers are never flushed to persistent storage using fsync() or FlushFileBuffers(). In other words, there is no attempt to make the direct-to-disk writes transactional or power-safe. We found that invoking fsync() or FlushFileBuffers() on each file written causes direct-to-disk storage to be about 10 times or more slower than writes to SQLite.
The next chart compares SQLite database updates in WAL mode against raw direct-to-disk overwrites of separate files on disk. The PRAGMA synchronous setting is NORMAL. All database writes are in a single transaction. The timer for the database writes is stopped after the transaction commits, but before a checkpoint is run. Note that the SQLite writes, unlike the direct-to-disk writes, are transactional and power-safe, though because the synchronous setting is NORMAL instead of FULL, the transactions are not durable.
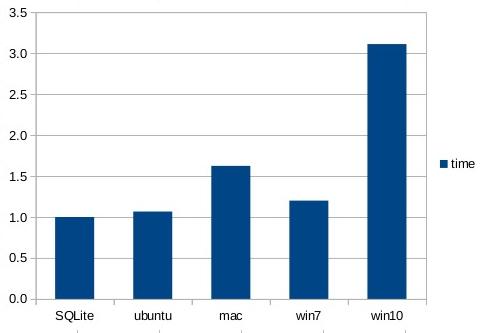
The android performance numbers for the write experiments are omitted because the performance tests on the Galaxy S3 are so random. Two consecutive runs of the exact same experiment would give wildly different times. And, to be fair, the performance of SQLite on android is slightly slower than writing directly to disk.
The next chart shows the performance of SQLite versus direct-to-disk when transactions are disabled (PRAGMA journal_mode=OFF) and PRAGMA synchronous is set to OFF. These settings put SQLite on an equal footing with direct-to-disk writes, which is to say they make the data prone to corruption due to system crashes and power failures.
In all of the write tests, it is important to disable anti-virus software prior to running the direct-to-disk performance tests. We found that anti-virus software slows down direct-to-disk by an order of magnitude whereas it impacts SQLite writes very little. This is probably due to the fact that direct-to-disk changes thousands of separate files which all need to be checked by anti-virus, whereas SQLite writes only changes the single database file.
The -DSQLITE_DIRECT_OVERFLOW_READ compile-time option causes SQLite to bypass its page cache when reading content from overflow pages. This helps database reads of 10K blobs run a little faster, but not all that much faster. SQLite still holds a speed advantage over direct filesystem reads without the SQLITE_DIRECT_OVERFLOW_READ compile-time option.
Other compile-time options such as using -O3 instead of -Os or using -DSQLITE_THREADSAFE=0 and/or some of the other recommended compile-time options might help SQLite to run even faster relative to direct filesystem reads.
The size of the blobs in the test data affects performance. The filesystem will generally be faster for larger blobs, since the overhead of open() and close() is amortized over more bytes of I/O, whereas the database will be more efficient in both speed and space as the average blob size decreases.
SQLite is competitive with, and usually faster than, blobs stored in separate files on disk, for both reading and writing.
SQLite is much faster than direct writes to disk on Windows when anti-virus protection is turned on. Since anti-virus software is and should be on by default in Windows, that means that SQLite is generally much faster than direct disk writes on Windows.
Reading is about an order of magnitude faster than writing, for all systems and for both SQLite and direct-to-disk I/O.
I/O performance varies widely depending on operating system and hardware. Make your own measurements before drawing conclusions.
Some other SQL database engines advise developers to store blobs in separate files and then store the filename in the database. In that case, where the database must first be consulted to find the filename before opening and reading the file, simply storing the entire blob in the database gives much faster read and write performance with SQLite. See the Internal Versus External BLOBs article for more information.
The kvtest program is compiled and run on Android as follows. First install the Android SDK and NDK. Then prepare a script named "android-gcc" that looks approximately like this:
#!/bin/sh # NDK=/home/drh/Android/Sdk/ndk-bundle SYSROOT=$NDK/platforms/android-16/arch-arm ABIN=$NDK/toolchains/arm-linux-androideabi-4.9/prebuilt/linux-x86_64/bin GCC=$ABIN/arm-linux-androideabi-gcc $GCC --sysroot=$SYSROOT -fPIC -pie $*
Make that script executable and put it on your $PATH. Then compile the kvtest program as follows:
android-gcc -Os -I. kvtest.c sqlite3.c -o kvtest-android
Next, move the resulting kvtest-android executable to the Android device:
adb push kvtest-android /data/local/tmp
Finally use "adb shell" to get a shell prompt on the Android device, cd into the /data/local/tmp directory, and begin running the tests as with any other unix host.
This page was last updated on 2025-11-13 07:12:58Z